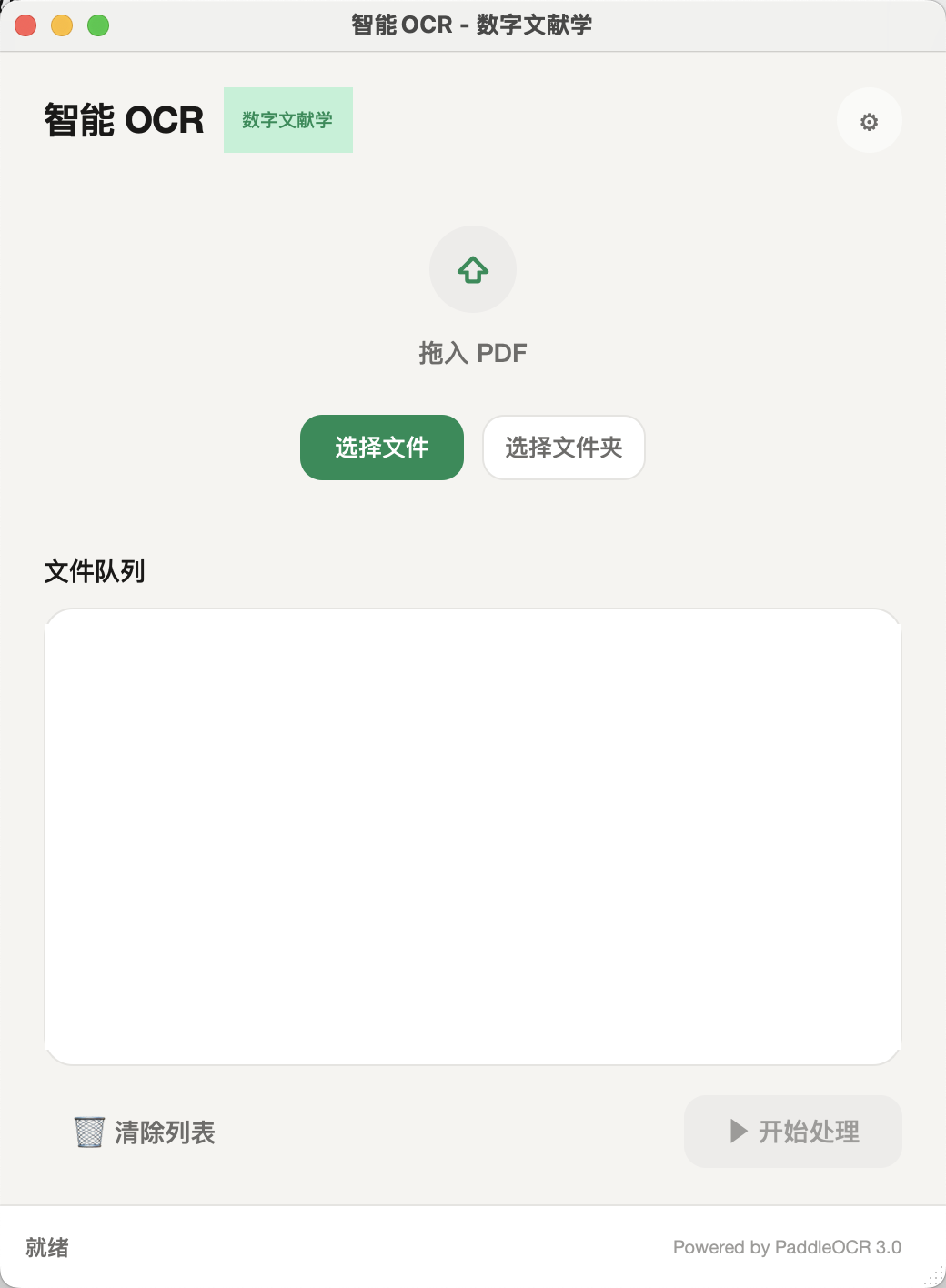
主界面:文件队列与批量处理
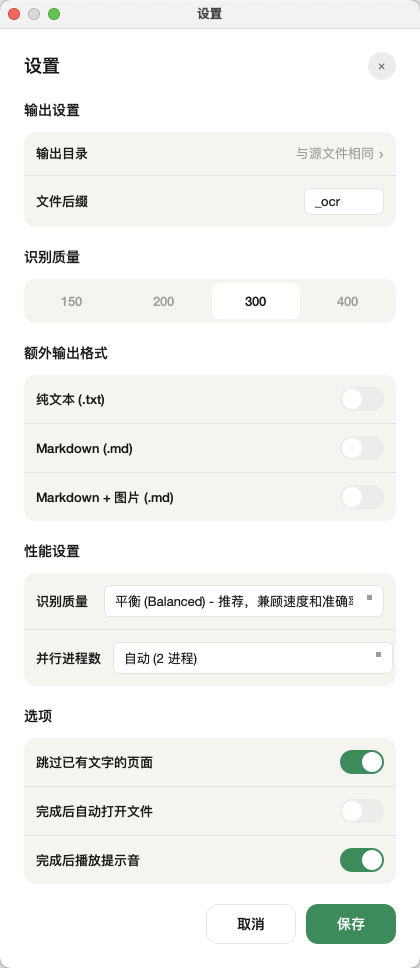
设置面板:识别质量与输出选项
Intelligent OCR
专为中文古籍与学术文献设计的高性能 OCR 桌面工具,将扫描版 PDF 转为全文可搜索格式,完全本地运行,保障文献隐私。
macOS 版提供 Apple Silicon(M 系列)与 Intel 两个版本,请按芯片类型选择;Windows 版支持 x64 系统。
由于本工具未经 Apple 公证(Notarization),macOS 的 Gatekeeper 在首次打开时会显示「无法打开,因为 Apple 无法检查其是否包含恶意软件」的提示。这是正常现象,按以下步骤操作即可。
方法一:系统设置(推荐)如果系统设置中看不到「仍要打开」按钮,可在终端执行以下命令解除隔离属性:
sudo xattr -rd com.apple.quarantine /Applications/OCR.app
(将 OCR.app 替换为实际文件名)输入 Mac 密码后回车,再次打开应用即可。
主界面:文件队列与批量处理
设置面板:识别质量与输出选项
大量古籍与学术文献以扫描 PDF 形式存档,无法全文检索、复制引用,严重制约数字人文研究的效率。现有云端 OCR 服务虽然便捷,但存在隐私泄露风险,且对古籍异体字、繁体字的识别准确率普遍不足。
研究者需要一款能在本地运行、专为中文古籍优化的高性能 OCR 工具,支持批量处理大规模文献,并内置异体字映射,使识别结果更符合学术检索需求。
工具采用高效的流水线架构,将 PDF 渲染与 OCR 识别解耦并行化:
本工具体现了两个数字文献学的核心理念:其一,离线工具保障文献隐私——珍贵古籍与未发表研究材料不应上传至云端,本地化工具是学术伦理的重要保障;其二,异体字处理是古籍 OCR 的核心挑战——同一字义在历史上存在大量书写变体,若不加映射,检索将严重失真,这是通用 OCR 工具难以解决而专项工具必须正视的问题。